
Staying ahead in today’s fast-moving tech landscape means understanding more than just headlines—it requires clarity on the systems, hardware shifts, and infrastructure decisions shaping tomorrow’s digital world. If you’re searching for practical insights into emerging hardware trends, archived tech protocols, and modern cloud infrastructure architecture, this article is designed to give you exactly that.
Technology evolves quickly, and outdated setups or overlooked innovations can create costly inefficiencies. Here, you’ll find a focused breakdown of key digital infrastructure developments, actionable setup guidance, and carefully analyzed innovation signals that matter right now.
Our insights are grounded in continuous monitoring of tech ecosystems, historical protocol analysis, and hands-on evaluation of infrastructure frameworks. By combining technical depth with practical application, this guide helps you make informed decisions—whether you’re optimizing existing systems or preparing for the next wave of digital transformation.
Start with an anecdote about a midnight outage that exposed brittle servers. I once watched a product launch stall because our cloud infrastructure architecture was stitched together like a sci‑fi prop (impressive, but fragile). That failure taught me resilience means redundancy—duplicate systems that prevent single points of failure—and observability, or real-time insight into system health. Meanwhile, some argue overengineering wastes money. Fair. Yet structured design actually curbs budget creep by forecasting load and automating scale. For example, auto-scaling groups expand during traffic spikes, then contract. Pro tip: document protocols early; future you will be grateful. Chaos is rarely scalable. Longterm.
First Principles: The Foundation of Modern Cloud Design
Modern cloud systems don’t fail because of ambition; they fail because of assumptions. So let’s start with the first principle.
1. Design for Failure
Traditional on-prem servers (A) assume stability; distributed systems (B) assume breakdowns. Designing for failure means building redundancy (duplicate components), failover mechanisms (automatic switching to backups), and distributed systems (workloads spread across nodes). Netflix’s Chaos Monkey famously tests this idea by intentionally breaking production systems (a bold move, but effective).
2. Decouple Everything
Monoliths (A) bundle everything together; microservices (B) separate functions into independent units. Decoupling—using APIs (application programming interfaces) and queues (message buffers that manage asynchronous tasks)—allows independent scaling and maintenance. In cloud infrastructure architecture, this separation prevents one service outage from cascading system-wide.
3. Automate Infrastructure
Manual provisioning (A) invites inconsistency; Infrastructure as Code (B) ensures repeatability. IaC means defining servers and networks in code for version control and disaster recovery.
4. Leverage Managed Services
Self-managed databases (A) demand patching and monitoring; managed services (B) offload that burden. Consequently, teams focus on business logic instead of server babysitting (which no one lists as a dream job).
The Five Pillars of a Well-Architected System
Security
Security isn’t a feature—it’s a posture. A well-architected system embeds protection at every layer: VPC segmentation, tightly scoped security groups, hardened IAM roles, and encryption in transit and at rest. Defense in depth (a layered security strategy where multiple safeguards back each other up) ensures that if one control fails, another stands guard. Some argue perimeter security is enough. It isn’t. Modern breaches often stem from misconfigured identities, not open ports (see Verizon DBIR reports). Pro tip: rotate IAM credentials automatically and audit least-privilege access quarterly.
Reliability
Reliability means systems recover gracefully and scale predictably. Auto-scaling adjusts compute capacity automatically based on demand, while load balancers distribute traffic to prevent overload. Multi-AZ deployments—spanning isolated data centers within a region—reduce single points of failure. Critics say redundancy is overkill for startups. Yet even brief outages can erode trust (just ask any SaaS hit during peak traffic). True resilience is engineered, not hoped for.
Performance Efficiency
Performance efficiency is about choosing the right tool for the job. ARM processors often deliver better price-performance for scalable workloads, while x86 may suit legacy dependencies. Storage tiers—hot, warm, cold—optimize speed versus cost. CDNs cache content closer to users, reducing latency (think Netflix buffering—now imagine it gone). Intelligent benchmarking separates guesswork from strategy.
Cost Optimization
Cost optimization is continuous, not reactive. Tag resources for visibility, right-size instances, commit to reserved capacity where predictable, and shut down idle environments. Some teams fear savings compromise performance. In reality, disciplined cost governance strengthens cloud infrastructure architecture without sacrificing agility.
Operational Excellence
Operational excellence turns strategy into repeatable success:
- Centralized logging
- Real-time monitoring
- Actionable alerts
- Automated CI/CD pipelines
Automation reduces human error and accelerates delivery. What gets measured improves—and what’s automated scales.
Choosing Your Abstraction Layer: IaaS, PaaS, & Serverless
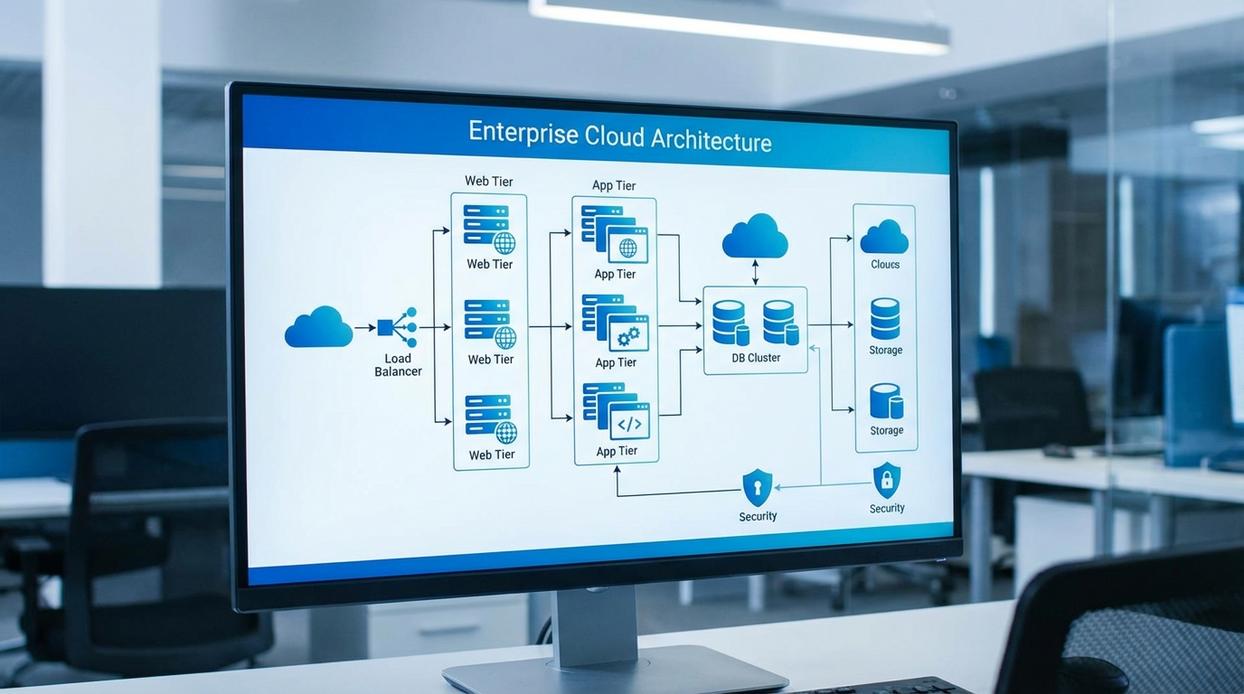
Choosing the right abstraction layer in cloud infrastructure architecture isn’t just technical—it’s philosophical.
Infrastructure as a Service (IaaS) means maximum control and maximum responsibility. You manage virtual machines, networking, and scaling (think EC2 or Compute Engine). It’s ideal for legacy systems or deeply customized stacks. Some argue IaaS is outdated because it’s operationally heavy. I disagree. When compliance, performance tuning, or specialized hardware matters, control wins.
Platform as a Service (PaaS) abstracts the servers away. You deploy code; the provider handles runtime and scaling (Heroku, Elastic Beanstalk). Critics say it limits flexibility. Sometimes true. But for rapid product launches, that constraint is a feature, not a bug (ask any startup racing to MVP).
Functions as a Service (FaaS/Serverless) runs event-driven code on demand (AWS Lambda, Google Cloud Functions). You pay per execution. It’s perfect for stateless workloads and microservices. Detractors point to cold starts and vendor lock-in—valid concerns—but for episodic traffic, the cost efficiency is hard to beat.
Making the Right Choice
- Limited ops team? Lean PaaS or Serverless.
- Complex legacy stack? Choose IaaS.
- Spiky workloads? Serverless shines.
Pro tip: match the tool to your team’s strengths, not just the trend.
For deeper context, see edge computing vs cloud computing key differences explained.
From Diagram to Deployment: Essential Tools and Protocols
Modern cloud infrastructure architecture no longer tolerates manual configuration. Infrastructure as Code (IaC)—the practice of managing infrastructure through machine-readable files—replaces fragile, click-by-click setups. Terraform uses a declarative approach (you define the desired end state, and it figures out the steps). In contrast, tools like AWS CloudFormation or Azure ARM templates often follow a more imperative style, where you specify exact actions. Some argue manual setup offers tighter control. However, version-controlled IaC improves repeatability, reduces drift, and prevents “it works on my machine” chaos (we’ve all been there).
Next, CI/CD pipelines act as automation engines:
- Code commit triggers a build
- Automated tests execute
- Successful tests deploy to staging or production
This protocol minimizes human error and accelerates delivery.
Finally, monitoring ensures visibility. Use Prometheus for metrics, ELK Stack for logs, and Jaeger for traces. Together, they provide actionable insight—because you can’t fix what you can’t see (even Batman needed surveillance).
Activating Your Architecture: Next Steps for Implementation
Now that the blueprint is clear, the real work begins. Think of this as A vs. B: reactive builds versus intentional design. Reactive systems grow messy and expensive. Intentional systems, built on documented pillars, stay resilient.
Start by drafting a design document grounded in cloud infrastructure architecture principles. Compare your options side-by-side:
- Manual provisioning vs. automated deployment
- Over-engineered stacks vs. right-sized abstractions
- Short-term fixes vs. scalable foundations
Granted, some argue documentation slows momentum. However, skipping structure often creates technical debt (and surprise invoices). So begin with the five pillars, choose the proper abstraction layer, and build forward with clarity.
As we delve into the complexities of modern cloud infrastructure architecture, it’s essential to consider how it intersects with critical security measures, such as those discussed in our article on Configuring a Firewall for Small Business Security.
Strengthen Your Infrastructure Before It Fails You
You set out to understand how modern systems stay fast, secure, and scalable — and now you have a clearer picture of what it takes to build and maintain resilient digital environments. From smarter deployment strategies to stronger security layers, you’ve seen how the right approach to cloud infrastructure architecture directly impacts performance, uptime, and long-term scalability.
The reality is this: outdated setups, fragmented systems, and reactive fixes cost time, money, and momentum. Falling behind on infrastructure innovation doesn’t just slow growth — it creates vulnerabilities that competitors won’t hesitate to exploit.
Now it’s time to act.
Audit your current infrastructure. Identify weak points. Modernize with scalable, future-ready frameworks. And if you want trusted insights on emerging hardware trends, archived tech protocols, and proven setup tutorials, explore our latest innovation alerts today.
Thousands of tech professionals rely on our guidance to stay ahead of rapid digital shifts. Don’t wait for system strain to force your hand — upgrade your strategy now and build infrastructure that’s ready for what’s next.
 There is a specific skill involved in explaining something clearly — one that is completely separate from actually knowing the subject. Jelvith Rothwyn has both. They has spent years working with digital infrastructure insights in a hands-on capacity, and an equal amount of time figuring out how to translate that experience into writing that people with different backgrounds can actually absorb and use.
Jelvith tends to approach complex subjects — Digital Infrastructure Insights, Tech Setup Tutorials, Knowledge Vault being good examples — by starting with what the reader already knows, then building outward from there rather than dropping them in the deep end. It sounds like a small thing. In practice it makes a significant difference in whether someone finishes the article or abandons it halfway through. They is also good at knowing when to stop — a surprisingly underrated skill. Some writers bury useful information under so many caveats and qualifications that the point disappears. Jelvith knows where the point is and gets there without too many detours.
The practical effect of all this is that people who read Jelvith's work tend to come away actually capable of doing something with it. Not just vaguely informed — actually capable. For a writer working in digital infrastructure insights, that is probably the best possible outcome, and it's the standard Jelvith holds they's own work to.
There is a specific skill involved in explaining something clearly — one that is completely separate from actually knowing the subject. Jelvith Rothwyn has both. They has spent years working with digital infrastructure insights in a hands-on capacity, and an equal amount of time figuring out how to translate that experience into writing that people with different backgrounds can actually absorb and use.
Jelvith tends to approach complex subjects — Digital Infrastructure Insights, Tech Setup Tutorials, Knowledge Vault being good examples — by starting with what the reader already knows, then building outward from there rather than dropping them in the deep end. It sounds like a small thing. In practice it makes a significant difference in whether someone finishes the article or abandons it halfway through. They is also good at knowing when to stop — a surprisingly underrated skill. Some writers bury useful information under so many caveats and qualifications that the point disappears. Jelvith knows where the point is and gets there without too many detours.
The practical effect of all this is that people who read Jelvith's work tend to come away actually capable of doing something with it. Not just vaguely informed — actually capable. For a writer working in digital infrastructure insights, that is probably the best possible outcome, and it's the standard Jelvith holds they's own work to.